CISC vs. RISC
- CISC (Complex Instruction Set Computer)
- 하나의 instruction으로 여러가지(복잡한) 작업 수행
- 가변 길이 instruction
- 장점: program size 작음
- 단점: cpu complexity 높음
- ex) x86(Intel, AMD), Motorola 68k
- RISC (Reduced Instruction Set Computer)
- 각각의 instruction이 작은(단위의) 작업 수행
- 고정 길이 instruction
- 장점: cpu complexity 낮음
- 단점: program size 큼
- ex) RISC-V, Arm, MIPS
Instruction 종류
- Data processing instructions (데이터처리 명령어)
- Arithmetic and Logical (Integer)
- 산술연산, 논리연산 등을 하기 위한 명령어
- Memory access instructions (메모리접근 명령어)
- Load/Store
- cpu가 데이터를 메모리에서 레지스터로 가져오는 명령어, 레지스터 값을 메모리에 쓰기위한 명령어
- 레지스터: 연산 전 잠깐 cpu에 가져오는 곳
- Branch instructions (분기 명령어)
- if, for, while 같은 조건문, 반복문이나 함수호출을 위한 명령어

Memory Hierarchy


CPU 동작 방식
- add x5, x6, x7 # x5 = x6 + x7
- x6과 x7은 피연산자, x5는 목적지
- 산술 명령어의 피연산자는 cpu 내부의 register라고 불리는 특별한 위치로부터 옴
- add x5, x6, 5 # x5 = x6 + 5
- 여기서 5는 immediate이며 숫자 5를 가리킴
- 산술 명령어의 피연산자는 immediate field에서도 올 수 있음
- 모든 cpu(x86, Arm, RISC-V)는 내부에 레지스터를 가짐
- RISC-V는 32*32-bit 레지스터를 가지고 있음

RV32I Register File
- 레지스터는 FF(Flip-Flops)로 구현되고 실행됨
- cpu 내부의 구조적인 레지스터 집합(프로그래머가 볼 수 있는 / 알 수 있는)을 레지스터 파일이라고 부름
- 레지스터 파일은 ff(이 수업에서 다룸) 또는 SRAM(실제 산업에서 쓰임)으로 구현 가능
- RV32I 레지스터 파일은 32*32bit 레지스터를 가짐
- 2 read ports
- 1 write ports
- 레지스터 파일에 대한 access는 메인메모리 또는 캐시에 대한 access보다 훨씬 빠름
- 왜냐하면 레지스터의 수자 제한되어 있고, cpu 내에 있기 때문
- 따라서 컴파일러들은 high-level 코드를 어셈블리 코드로 변환할 때 레지스터 파일을 사용하려 함

RISC-V Register Convention

RISC-V Instruction Formats
- Arithmetic and Logical (Integer)
- Load/Store
- Jump and Branch


R-type Instruction

- opcode
- 7-bit (128 종류 나타낼 수 있음)
- operation(ex. and, or, xor, +, -, load, store 등) code
- funct7
- 7-bit
- opcode와 함께 명령어가 어떤 동작을 하는지 명시하는 부분
- funct3
- 3-bit
- opcode와 함께 명령어가 어떤 동작을 하는지 명시하는 부분
- rs1
- 5-bit
- register of the first sorce operand
- rs2
- 5-bit
- register of the second sorce operand
- rd
- 5-bit
- register of the destination operand
- 레지스터의 개수가 32개이므로 32개 중 1개를 명시하려면 최소한 5-bit(2^5 = 32) 필요
add



sub

I-type Instruction

- R-type 명령어는 레지스터에 3개의 피연산자를 모두 갖고있음
- I-type 명령어에서는 하나의 피연산자를 명령어 자체에 저장할 수 있음 => immediate(즉치값)
- Immediate
- 레지스터나 메모리 접근이 필요x
- 12-bit의 immediate 필드는 2의 보수법을 사용하므로 -2^11 ~ 2^11-1로 값이 제한되어있음
- R-type과 비교했을 때 funct7과 rs2가 없음
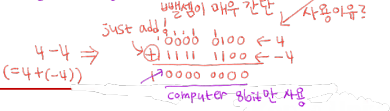
2's Complement Number
- 2의 보수법은 부호가 있거나 없는 숫자의 덧셈과 뺄셈을 하는 편리하고 간단한 방법을 제공
- 2의 보수를 얻는 빠른 방법은 모든 bit를 뒤집고 1을 더하면 됨



addi

Logical Instructions
- and, or, xor, andi, ori, xori
- 논리 명령어는 2개의 source 피연산자를 bit 별로 연산하고 그 결과를 목적 레지스터에 기록함




R-type Instruction (and, or, xor)

I-type Instruction (andi, ori, xori)

Sign Extension
- I-type 에서 immediate는 12bit임
- 하지만 source 레지스터의 크기는 32bit임
- 따라서 12bit인 immediate를 32bit로 늘려줘야함
- 이를 Extension이라함
- Zero-extension
- 나머지 20bit를 전부 0으로 채움
- (음수일 때) 숫자가 바뀜
- Sign-extension
- 12bit의 가장 앞 bit를 MSB(Most significant Bit)라 함
- 이 MSB를 20bit에 전부 채워넣음
- 숫자 바뀌지 않음
- 일반적인 CPU에서
- arithmetic inst => SE 사용
- logical inst => ZE 사용
- RISC-V에서는 둘다 SE 사용 (ZE 사용하는 것이 큰 이점이 X)

Shifting



Shift Instructions
- sll : shift-left logical
- srl: shift-right logical
- sra: shift-right arithmetic (sla는 없음, sll이랑 똑같음)
- slli: shift-left loghical immediate
- srli
- srai